Hace mucho tiempo que quería tener una estación meteorológica, para saber en todo momento qué temperatura hay, si sopla el viento o si está lloviendo. Es algo muy útil para múltiples temas domóticos. Por ejemplo, sería fantástico que cuando se ponga a llover, o el viento supere un cierto umbral, me llegue un Telegram diciéndome que ojo, que está el tiempo revuelto, mira a ver si tienes todas las persianas cerradas y nada que se pueda mojar.
Pero te pones a rascar, y resulta que la mayoría de estos productos son notablemente cerrados: la mayoría sólo te muestra la información en alguna pantallita, o una aplicación de móvil como mucho. E incluso las que tienen un programa desde el que procesar la información, acostumbra a ser un programa propio, desde el que es difícil exportar la información a otras historias.
Pero un día me encontré un post en Reddit que explicaba algo muy interesante: resulta que la mayoría de estaciones meteorológicas que tienen una unidad exterior (con los sensores) y otra interior (pantallita con los datos) se comunican entre sí mediante una comunicación por radio, que se puede «interceptar» fácilmente con un pincho USB de 15 eur, y que luego, usando el software adecuado, se puede decodificar para extraer la información. Es una cosa que parece muy hacker, pero la verdad es que es todo muy sencillo de montar, y funciona de maravilla. Al lío entonces:
La estación
En lo que respecta a la estación meteorológica que escoger, obviamente hay que elegir una que sea «hackeable». Para eso lo más fácil es ir al final de la cadena, al software que decodifica la información, y ver qué modelos soporta. Yo elegí la Bresser 5in1, primero porque era la que se explicaba en el post de Reddit, pero también porque mide exactamente lo que yo quería (temperatura y humedad, viento y lluvia), y además tengo otros productos de la marca y me gusta.

La instalación del aparato ya es un tema aparte, pero en el fondo es sencillo: la unidad exterior se planta en un poste, y la unidad interior es una pantallita que muestra los datos de temperatura, viento, lluvia y demás. Los dos aparatos funcionan con pilas, que ya veremos lo que duran. Tengo en mente un hackeo extra para alimentar al menos la unidad exterior desde la red, porque tener que bajar el aparato del poste, aunque sea cada X meses, no deja de ser una molestia. Pero eso ya es carne para otro post.
El aparato para leer la señal
Una vez esté la estación meteorológica montada y funcionando, ya estamos en disposición de capturar la señal. Para eso lo que necesitamos es simplemente un stick USB sintonizador de TV, pero no uno cualquiera, sino uno con un chipset específico, en concreto un Realtek RTL2832.

Yo he comprado este, pero porque soy un ansias y lo quería ya. A mí me costó como 15 eur, pero si lo compras en China y no te importa esperar un mes, se puede conseguir por unos 5 euritos fácil.
Ojo, que es importante que venga con la típica antenita moñas, la típica que cuando quieres usar el stick para ver la TV no vale para nada. Para ver la TV no valdrá, pero para captar la señal de radio es ideal.

La instalación en cualquier linux moderno es trivial, no hay que hacer nada especial. Lo único es asegurarse que, al enchufar, se establezcan los permisos correctos. Para eso hay que añadir una línea como la siguiente en el fichero /etc/udev/rules.d/20.rtlsdr.rules:
SUBSYSTEM=="usb", ATTRS{idVendor}=="0bda", ATTRS{idProduct}=="2838", GROUP="adm", MODE="0666", SYMLINK+="rtl_sdrSUBSYSTEM=="usb", ATTRS{idVendor}=="0bda", ATTRS{idProduct}=="2838", GROUP="adm", MODE="0666", SYMLINK+="rtl_sdr""
Con esto, sólo hay que asegurarse de que nuestro usuario está en el grupo adm (sudo adduser usuario adm si no es así), y ya debería funcionar bien.
El software
Con la estación montada y el stick USB enchufado y configurado, ya sólo falta leer los datos. Para eso hace falta el comando rtl_433, que es el programa que coge la señal, la interpreta y busca patrones conocidos para decodificarlos. Soporta dispositivos a cascoporro, que se pueden consultar en su página web o desde la misma ayuda del programa.
La instalación del programa es trivial en cualquier linux moderno, ya que suele estar en los repositorios:
sudo apt-get install rtl_433
Y listos. Si lo ejecutamos tal cual, nos mostrará esto:
usuario@maquina:~$ rtl_433 rtl_433 version 20.11-43-g61d24ba9 branch master at 202101281106 inputs file rtl_tcp RTL-SDR Use -h for usage help and see https://triq.org/ for documentation. Trying conf file at "rtl_433.conf"… Trying conf file at "/home/pi/.config/rtl_433/rtl_433.conf"… Trying conf file at "/usr/local/etc/rtl_433/rtl_433.conf"… Trying conf file at "/etc/rtl_433/rtl_433.conf"… Registered 147 out of 177 device decoding protocols [ 1-4 8 11-12 15-17 19-21 23 25-26 29-36 38-60 63 67-71 73-100 102-105 108-116 119 121 124-128 130-149 151-161 163-168 170-175 177 ] Detached kernel driver Found Rafael Micro R820T tuner Exact sample rate is: 250000.000414 Hz [R82XX] PLL not locked! Sample rate set to 250000 S/s. Tuner gain set to Auto. Tuned to 433.920MHz. Allocating 15 zero-copy buffers
Aquí se ve como detecta el stick, y empieza a escanear. Pero aquí no encuentra nada, porque probablemente la frecuencia que usa por defecto no es la de nuestro aparato, y además no es muy eficiente porque está escaneando 177 protocolos distintos a la vez, cuando bastaría que buscase el de nuestro aparato (a no ser que queramos hackear la estación del vecino, que también es una opción 🙂 ). En mi caso, el comando mágico para mi estación es el siguiente:
usuario@maquina:~$ rtl_433 -f 868300000 -R 119 -Y classic -C si rtl_433 version 20.11-43-g61d24ba9 branch master at 202101281106 inputs file rtl_tcp RTL-SDR Use -h for usage help and see https://triq.org/ for documentation. Trying conf file at "rtl_433.conf"… Trying conf file at "/home/pi/.config/rtl_433/rtl_433.conf"… Trying conf file at "/usr/local/etc/rtl_433/rtl_433.conf"… Trying conf file at "/etc/rtl_433/rtl_433.conf"… New defaults active, use "-Y classic -s 250k" for the old defaults! Registered 1 out of 177 device decoding protocols [ 119 ] Detached kernel driver Found Rafael Micro R820T tuner Exact sample rate is: 1000000.026491 Hz [R82XX] PLL not locked! Sample rate set to 1000000 S/s. Tuner gain set to Auto. Tuned to 868.300MHz. Allocating 15 zero-copy buffers time : 2021-01-30 17:16:21 model : Bresser-5in1 id : 106 Battery : 1 Temperature: 17.2 C Humidity : 63 Wind Gust : 2.0 m/s Wind Speed: 2.3 m/s Direction : 202.5 Rain : 29.2 mm Integrity : CHECKSUM time : 2021-01-30 17:16:57 model : Bresser-5in1 id : 106 Battery : 1 Temperature: 17.2 C Humidity : 64 Wind Gust : 4.0 m/s Wind Speed: 2.4 m/s Direction : 157.5 Rain : 29.2 mm Integrity : CHECKSUM
Aquí ya hemos restringido la búsqueda sólo al protocolo de nuestra estación, y hemos establecido la frecuencia que toca (que al final es la que pone en las especificaciones del aparato). Así ya vemos que empieza a encontrar información, y por defecto las muestra por pantalla.
Pero esto no es todo, la gracia de rtl_433 es que tiene un montón de formas de procesar la información que decodifica. Y como sólo ver por pantalla los datos tampoco es demasiado útil, lo suyo es sacarlos de otra manera. Y en un contexto domótico, lo mejor es exportar la información por MQTT, porque así es directamente integrable en cualquier otra plataforma, ya sea Home Assistant, NodeRED, o lo que sea. En mi caso, se le añade un parámetro al comando:
rtl_433 -f 868300000 -R 119 -Y classic -F "mqtt://servidor:puerto,user=usuario,pass=contraseña,events=rtl_433/events,states=rtl_433/states,devices=rtl_433/devices[/model]" -C si
Obviamente hay que tener un servidor MQTT montado, pero vamos, montarse un mosquitto son 5 minutos.
Ya para rematar la cuestión, si lo que queremos es dejar esto funcionando las 24h, lo suyo es añadir este comando como un servicio que se arranque automáticamente al inicio de la máquina. Para esto se puede crear un servicio systemd creando un fichero /etc/systemd/system/rtl_433.service con el contenido:
[Unit] Description=rtl_433 After=network.target [Service] Type=simple User=pi ExecStart=/usr/local/bin/rtl_433 -f 868300000 -R 119 -Y classic -F "mqtt://servidor:puerto,user=usuario,pass=contraseña,events=rtl_433/events,states=rtl_433/states,devices=rtl_433/devices[/model]" -C si RestartSec=0 Restart=always RemainAfterExit=no [Install] WantedBy=multi-user.target
Y una vez creado el fichero, lo arrancamos y establecemos que se ejecute automáticamente en el arranque:
sudo systemctl start rtl_433 sudo systemctl enable rtl_433
Y ya está todo. Si nos suscribimos al topic de MQTT, veremos cómo van saliendo valores:
usuario@maquina:~$ mosquitto_sub -v -u usuario -P contraseña -t "rtl_433/#"
rtl_433/events {"time":"2021-01-30 17:55:57","model":"Bresser-5in1","id":106,"battery_ok":1,"temperature_C":18.2,"humidity":63,"wind_max_m_s":3.0,"wind_avg_m_s":2.1,"wind_dir_deg":202.5,"rain_mm":29.2,"mic":"CHECKSUM"}
rtl_433/devices/Bresser-5in1/time 2021-01-30 17:55:57
rtl_433/devices/Bresser-5in1/id 106
rtl_433/devices/Bresser-5in1/battery_ok 1
rtl_433/devices/Bresser-5in1/temperature_C 18.2
rtl_433/devices/Bresser-5in1/humidity 63
rtl_433/devices/Bresser-5in1/wind_max_m_s 3.0
rtl_433/devices/Bresser-5in1/wind_avg_m_s 2.1
rtl_433/devices/Bresser-5in1/wind_dir_deg 202.5
rtl_433/devices/Bresser-5in1/rain_mm 29.2
rtl_433/devices/Bresser-5in1/mic CHECKSUM
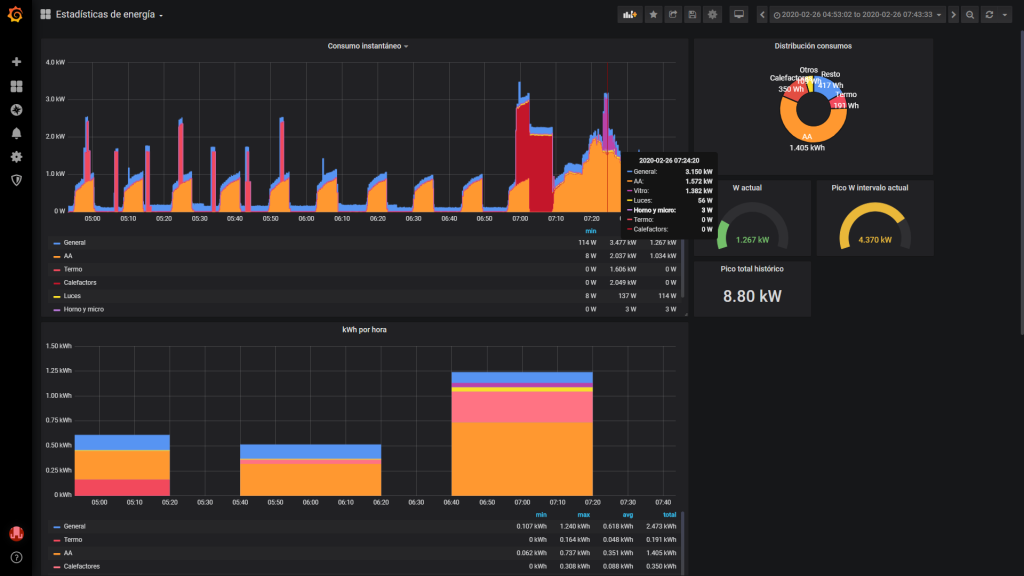
Con todo montado, ya podemos leer los datos desde cualquier plataforma que soporte MQTT (y la que no lo soporte no merece existir), y hacer lo que queramos con los datos. Yo por ejemplo de momento me dibujo cuatro gráficas con Grafana:

Como remate final, en mi caso si ponía el stick USB donde tengo el servidor, no me llegaba bien la señal, por lo que pasé todo el sistema a una Raspberry Pi, para poder ponerla más cerca de la estación exterior. El proceso viene a ser el mismo, la única diferencia es que el comando rtl_433 no está en los repositorios, y hay que compilarlo a mano. Siguiendo las instrucciones es muy sencillo.
Me preocupaba que una Raspberry Pi no tuviera potencia para decodificar la señal, pero teniendo en cuenta que uso la Raspberry Pi Zero, que es la menos potente de la familia, veo que la CPU se queda en un 50%, por lo que va más que sobrada. Si se usa cualquier ordenador normal el consumo de CPU es totalmente irrisorio, en mi servidor no llegaba al 2%, y eso que tiene un Celeron fanless de bajo consumo.
A partir de aquí, a hacer automatizaciones se ha dicho. Tampoco está de más, ya que lo tenemos todo montado, subir nuestros datos a MeteoClimatic y compartirlos con quien los pueda necesitar, pero eso lo dejo para otro post.