Bueno, en la entrada anterior contaba lo súper fantabuloso que es el Shelly EM como medidor de consumo energético, lo abierto que es y lo fácil que es integrarlo con casi cualquier cosa. Pues ahora falta ver la otra parte: cómo podemos coger los datos de consumo, y visualizarlos de forma bonita y vistosa.
Veamos, esta va a ser una entrada densa, porque hay que introducir muchos conceptos y hay muchas piezas interconectadas. Aunque pueda parecer todo muy complejo, en el fondo no es tan difícil, y la gracia es que, una vez montado el tinglado inicial, luego ir añadiendo cosas es trivial.
Pero al lío. Para poder llegar a ver gráficas chulas, hay que pasar por todas las fases:
- Tener un medidor de consumo que nos dé los datos en un formato abierto y procesable: Chachi, eso ya lo tenemos, partiré de que tenemos un Shelly EM publicando los datos por HTTP o MQTT. Obviamente, cualquier otro medidor que proporcione los datos por una vía equivalente es igual de válido.
- Ahora hay que recibir los datos de alguna manera. Lo más chulo y versátil para estas cosas domóticas es usar Node-RED (luego más).
- Los datos hay que almacenarlos en alguna parte. Podríamos usar cualquier base de datos en plan MySQL, ficheros de texto o lo que sea, pero teniendo en cuenta que este tipo de datos crecen una barbaridad, lo más apropiado es usar una base de datos específica para guardar series temporales, como InfluxDB.
- Y ahora que ya tenemos los datos guardaditos, ya podemos hacer gráficas, en este caso con Grafana.
Madre del amor hermoso, menuda movida para ver cuatro gráficas. ¿De verdad vale la pena? ¿No sería más feliz viendo las gráficas en el típico cacharrín propietario mientras dure su app? Afortunadamente, instalar todo esto es 1.000 veces más fácil que si lo hiciéramos a pelo, gracias a…
Docker
¿Ein? ¿No hablábamos de medir energía, de domótica y de instalar programas? Pues ahí andamos, porque resulta que Docker es una forma de instalar en dos patadas programas que serían tremendamente complicados de instalar si se hiciera a pelo.
El concepto de los contenedores Docker reconozco que es espinoso. Para el que esté familiarizado con el concepto de máquina virtual, se podría decir que un contenedor Docker es una especie de máquina virtual, pero «aligerada». Porque si una máquina virtual viene a ser un «miniordenador», con un sistema operativo entero y las aplicaciones que hagan falta, un contenedor Docker vendría a ser el resultado de «podar» esta máquina virtual y dejarla estrictamente con lo que necesita para ejecutar una aplicación concreta. Por eso con las máquinas virtuales hablamos de sistemas operativos (una máquina virtual con Ubuntu, o con Windows) pero con contenedores hablamos de aplicaciones (un contenedor con MySQL, o con Transmission).
La gracia extra de los contenedores es que, a diferencia de las máquinas virtuales, para las que se reserva una porción de memoria y unas cuantas CPUs, los contenedores se ejecutan todos sobre la misma máquina, compartiendo kernel, memoria y recursos. La argucia técnica que permite hacer eso aislando al mismo tiempo unos contenedores de otros lo dejo para otro día, pero el caso es que esta diferencia hace que arrancar o parar contenedores sea rapidísimo, comparado con una máquina virtual.
Otra ventaja de los contenedores es que tenemos dos cosas:
- Un repositorio en internet (Docker Hub) de contenedores ya hechos, para casi cualquier aplicación que se nos ocurra.
- Herramientas para orquestar el arranque de varios contenedores enchufados entre ellos, simplemente escribiendo un ficherito de texto.
O sea, que al final es raro que hagamos contenedores a pelo. Más bien cogeremos contenedores ya hechos, con los programas que nos interesen, y los configuraremos e interconectaremos para conseguir lo que queramos.
Como esto es muy teórico, se ve mucho mejor con un ejemplo. Pongamos que quiero montarme un blog con WordPress. Tradicionalmente, empezaríamos a instalar todos los requisitos: que si un Apache, que si el soporte de PHP, una base de datos MySQL… Y luego ponte a configurar todo.
Usando contenedores, bastaría crear un ficherito llamado docker-compose.yaml, tal que asín:
version: '3.3'
services:
db:
image: mysql:5.7
volumes:
- db_data:/var/lib/mysql
restart: always
environment:
MYSQL_ROOT_PASSWORD: somewordpress
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpress
MYSQL_PASSWORD: wordpress
wordpress:
depends_on:
- db
image: wordpress:latest
ports:
- "8000:80"
restart: always
environment:
WORDPRESS_DB_HOST: db:3306
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: wordpress
WORDPRESS_DB_NAME: wordpress
volumes:
db_data: {}
Con esto le estoy diciendo que quiero dos contenedores, uno con una BD MySQL, y otro con un WordPress. Y luego para cada uno configuro cuatro cosas: que si usuarios/passwords de la BD, que si en qué puerto servirá… El caso es que, una vez tengo esto, basta ejecutar:
docker-compose up
Y él solo ya se encargaría de bajarse los contenedores que le he indicado (wordpress y MySQL), configurarlos según mis instrucciones y ejecutarlos, con lo que ya puedo abrir el navegador, apuntar al puerto que corresponda, y ya tengo mi WordPress en marcha.
Chachi, ¿no? Pues después de la introducción, vamos a utilizar esto mismo para montarnos en dos patadas nuestro tinglado domótico.
Primer paso: Node-RED
Node-RED es… una cosa difícil de describir. Se podría decir que es una plataforma para interconectar diferentes sistemas de forma visual, a base de unir cajitas con líneas. Es una descripción poco científica, pero de verdad que es más fácil verlo y probarlo que intentar describirlo con palabras.
En nuestro caso, lo vamos a usar para coger lo que nos envíe el medidor de consumo, y enviarlo a nuestra base de datos.
Como hemos dicho, vamos a montarlo todo con Docker. Nos vamos a cualquier directorio, y editamos el fichero docker-compose.yaml, con el siguiente contenido:
version: "3.3"
services:
nodered:
image: nodered/node-red
container_name: nodered
restart: unless-stopped
user: "1000"
volumes:
- $PWD/data:/data
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/TZ:ro
environment:
- TZ=Europe/Madrid
ports:
- 1880:1880
Con esto le estamos diciendo que queremos un Node-RED en el puerto 1880, que queremos que guarde los datos en el subdirectorio data, y luego le hemos añadido un par de cosas para que tenga bien los permisos de los ficheros, coja bien la hora y esté siempre arrancado aunque reiniciemos el servidor.
Y ya está. Ejecutamos «docker-compose up», y ya deberíamos tener Node-RED en marcha.
Como la idea de Node-RED es enganchar el medidor con la base de datos, vamos a instalar esta última antes de configurar nada.
InfluxDB
InfluxDB es una base de datos como tantas, pero con una particularidad: está optimizada para guardar series temporales. ¿Qué quiere decir eso? Pues que si una base de datos normal guarda todos los datos en un registro de tamaño fijo, y tenemos muchos datos, eso va a ocupar un montón con el tiempo. Lo que hace InfluxDB es guardar las diferencias entre un dato y otro, de una forma muy compacta, de manera que lo que en otra base de datos ocuparía GB, aquí ocupa MB. Ideal para nuestro caso de guardar consumos eléctricos ad-infinitum.
Para instalarlo, volvemos a abrir el docker-compose.yaml, y añadimos un servicio nuevo, para InfluxDB:
version: "3.3"
services:
nodered:
image: nodered/node-red
container_name: nodered
restart: unless-stopped
user: "1000"
volumes:
- $PWD/data:/data
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/TZ:ro
environment:
- TZ=Europe/Madrid
ports:
- 1880:1880
influxdb:
image: influxdb:latest
container_name: influxdb
environment:
- TZ=Europe/Madrid
- INFLUXDB_DB=energia
- INFLUXDB_ADMIN_USER=influxdb
- INFLUXDB_ADMIN_PASSWORD=influxdb
- INFLUXDB_WRITE_USER=influxdb_w
- INFLUXDB_WRITE_PASSWORD=influxdb_w
- INFLUXDB_HTTP_FLUX_ENABLED=true
ports:
- 8086:8086
- 8083:8083
- 2003:2003
volumes:
- $PWD/influxdb:/var/lib/influxdb
restart: unless-stopped
Y ya está. Sólo le hemos indicado el nombre de la base de datos («energia») y hemos indicado que cree dos cuentas de usuario: una para administrar, y otra sólo con permisos de escritura, que será la que usemos para cargar los consumos.
Si volvemos a ejecutar docker-compose, veremos cómo se descarga y arranca la BD.
Enviar consumos a InfluxDB con Node-RED
Ahora que ya tenemos la BD en marcha, vamos a usar Node-RED para leer los consumos del medidor, y enviarlos a InfluxDB. Para esto abrimos Node-RED, y tenemos que añadir dos nodos al tablero: uno para leer del medidor, y otro para escribir en InfluxDB. Los unimos con una flechita, y listos:
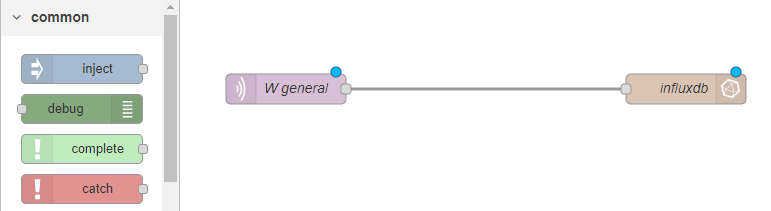
Hay que clicar en cada uno de los nodos, y configurar ahí lo que haga falta.
En el caso del medidor, yo leo los valores por MQTT, por lo que habría que indicar a qué «topic» escribe el medidor. Si se quisiera hacer por HTTP, habría que usar otro tipo de nodo, e indicar la URL y la frecuencia de lectura. Es un poco más complicado, sería algo así:

En vez de esperar a que llegue el valor, al leerlo por una web hay que leer periódicament (nodo timestamp, configurado para leer cada 10 segundos o así), luego hacer la petición (nodo http request) y luego, de entre todo lo que nos llega, sacar el consumo en W (nodo tipo Change, cogiendo el valor «power»).
En el caso del nodo de influxdb, hay que indicar el host y el puerto en los que tenemos la base de datos (son los valores que hemos indicado en docker-compose.yaml), así como el usuario y contraseña definidos antes.
Con esto ya tenemos los consumos eléctricos guardados en nuestra base de datos. Ahora sólo queda hacer gráficas.
Grafana
Grafana es una aplicación web para hacer gráficas chulas en tiempo real. Permite recuperar los datos de un montón de fuentes diferentes, entre ellas InfluxDB. Para añadir una instancia de Grafana a nuestro Docker, simplemente habría que añadir un servicio más a nuestro docker-compose.yaml:
version: "3.3"
services:
nodered:
image: nodered/node-red
container_name: nodered
restart: unless-stopped
user: "1000"
volumes:
- $PWD/data:/data
- /etc/localtime:/etc/localtime:ro
- /etc/timezone:/etc/TZ:ro
environment:
- TZ=Europe/Madrid
ports:
- 1880:1880
influxdb:
image: influxdb:latest
container_name: influxdb
environment:
- TZ=Europe/Madrid
- INFLUXDB_DB=energia
- INFLUXDB_ADMIN_USER=influxdb
- INFLUXDB_ADMIN_PASSWORD=influxdb
- INFLUXDB_WRITE_USER=influxdb_w
- INFLUXDB_WRITE_PASSWORD=influxdb_w
- INFLUXDB_HTTP_FLUX_ENABLED=true
ports:
- 8086:8086
- 8083:8083
- 2003:2003
volumes:
- $PWD/influxdb:/var/lib/influxdb
restart: unless-stopped
grafana:
image: grafana/grafana:latest
container_name: grafana
depends_on:
- influxdb
environment:
- TZ=Europe/Madrid
- GF_SERVER_ROOT_URL=https://midominio/grafana
- GF_SERVER_SERVE_FROM_SUB_PATH=true
- GF_SECURITY_ADMIN_USER=miusuario
- GF_SECURITY_ADMIN_PASSWORD=passadmin
- GF_ENABLE_ALPHA=true
- GF_INSTALL_PLUGINS=grafana-influxdb-flux-datasource,grafana-piechart-panel
volumes:
- $PWD/grafana-storage:/var/lib/grafana
ports:
- 3000:3000
restart: unless-stopped
Que viene a ser más de lo mismo que ya hemos visto: cuatro configuraciones sobre usuarios y compañía, puertos y directorio donde ser guardarán los datos. Aquí hay un par de cosas adicionales que no son imprescindibles: unos cuantos plugins extras que no vienen de serie, y un par de configuraciones en las que le indico un dominio, para poder acceder a la instancia de Grafana desde fuera de mi red local. Pero vamos, que no hacen falta.
Con esto arrancamos Grafana, y ya podríamos configurar un datasource de tipo InfluxDB e ir añadiendo gráficas con lo que nos apetezca. En esto no voy a entrar porque esta entrada ya queda demasiado larga, hay guías a patadas sobre cómo usar Grafana, cada cuál tiene sus gustos y en el fondo el interfaz es muy intuitivo y amigable. Sólo pongo un pantallazo de cómo queda mi configuración de monitorización de energía:
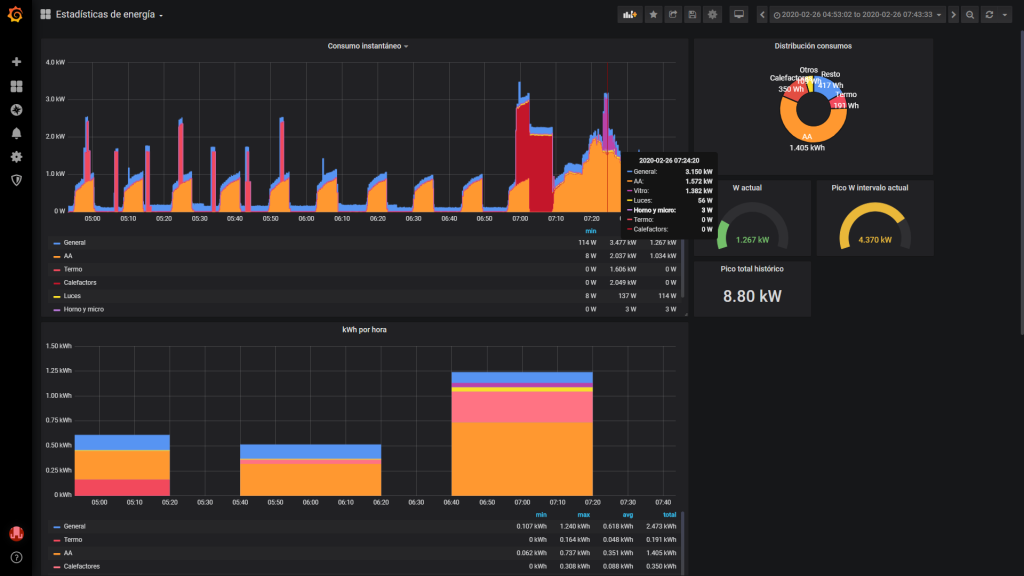
Chulo, ¿verdad? Y actualizado en tiempo real y totalmente interactivo para cambiar el intervalo de tiempo a analizar, hacer zoom o quitar o poner medidas. Bueno, en mi caso es un poco trampa, porque no tengo un solo Shelly EM, sino dos, midiendo cuatro circuitos, más un Shelly 1PM para medir las luces, más dos Shelly Plug S para medir los calefactores del baño, más un TP-Link HS-110 (este no es tan abierto como los Shellys, pero se puede usar con Node-RED Home Assistant mediante) para medir el termo… Si es que esto de ponerse a monitorizar es empezar, y no querer parar 🙂
En definitiva, que en dos patadas y gracias a Docker nos hemos montado un tinglado considerable, muy fácil de instalar y mantener. ¿Que mañana cambiamos el servidor? Pues cogemos el docker-compose.yaml, lo copiamos al nuevo, y con un docker-compose up lo tenemos todo de nuevo en marcha en segundos. Así da gusto instalar cosas.
