Últimamente se oye mucho hablar de los ataques ransomware, que consisten básicamente en que un pérfido hacker entra en tu ordenador, cifra todos tus datos, y te pide una cantidad considerable de dinero si los quieres de vuelta. Como se comenta siempre que se habla de este tema, la mejor solución para no ser vulnerable a estas cosas (aparte de cuidar la seguridad al máximo para que no te entren, claro) es tener una buena política de copias de seguridad. Así, si todo falla y alguien te entra hasta la cocina y secuestra tus datos, pues lo borras todo, restauras desde la última copia, y a otra cosa.
Pero no es tan sencillo como esto, porque estos delincuentes no son tontos, y también tienen sus técnicas, con lo que generalmente no se limitan a entrar, cifrar y chantajear. Más bien, una vez entran en tus sistemas, miran bien lo que hay, se quedan unos días analizando lo que haces, y especialmente buscan si tienes algún tinglado automático de copias de seguridad (como deberías estarhaciendo). Y si lo encuentran, se ocupan de borrarte las copias antes de hacer público el chantaje, con lo que, a la hora de la verdad, te puedes encontrar compuesto y sin copias.
¿Qué hacer en estos casos? Porque es muy normal tener, en los propios scripts/programas que hacen las copias, las contraseñas de acceso al servicio, ya que de alguna forma hay que autenticarse. Incluso si se usa algo más virguero como un gestor de contraseñas o autenticación con claves SSH, generalmente se usa una clave sin contraseña, ya que, para que un backup funcione, tiene que ser automático. Si cada vez que va a hacer una copia hay que poner una contraseña a mano, se fastidia todo el tinglado. Lo que pasa es que, teniéndolo así, es trivial que el intruso encuentre la contraseña y borre todas las copias. Pero tranquilidad, que hay formas de gestionar esto mejor.
Primera opción: confiar en el backend
Una primera opción es, directamente, confiar en el servicio de copias. Si usamos Dropbox, o el mismo Backblaze B2 como sitio donde guardar las copias, generalmente suelen tener una política de guardado de ficheros borrados, y te permiten acceder a las cosas borradas durante un tiempo, como 30-60 días. Eso por sí solo, en realidad, sólo está aplazando el problema, porque el intruso puede entrar, borrar las copias, esperar a que expire el plazo, y luego atacar. Por tanto, es importante, si confiamos en este sistema, tener los backups monitorizados, de manera que recibamos algún tipo de aviso en caso de que pasen X días sin copias. En ese caso, es señal de que algo turbio está pasando, y podremos actuar. Realmente, monitorizar las copias es algo saludable en cualquier caso, ya que puede que el sistema de backups haya dejado de funcionar por cualquier chorrada, y si no nos damos cuenta, no estamos protegidos.
Pero ojo, porque igual que un intruso puede desactivar/borrar las copias, también puede desactivar/falsear la monitorización y los avisos. Vamos, que está bien que el backend soporte recuperar cosas borradas, y a veces es suficiente con hacerle un poco difícil al atacante la tarea para que se vaya a probar a otro sitio, pero hay que tener claro que esto no es una solución infalible.
Otra opción: hacer imposibles los borrados
Si queremos ir un poco más allá, y securizar de verdad las cosas, hay que prevenir antes que curar. No pensar en qué haremos cuando nos borren las cosas, sino impedir que se borren directamente. Y justamente es una opción que admiten según qué backends de copias: permitir sólo la subida de archivos, pero no el borrado.
En mi caso, después de experimentar con muchossistemas, actualmente hago mis backups con borg, subiendo los ficheros a BorgBase. Y BorgBase, cuando configuras un repositorio y le indicas qué claves SSH tienen permiso para trabajar con él, permite definir dos tipos de claves:
Full access: Podrán hacer cualquier cosa, desde subir ficheros a modificar/borrar. Son las que se suelen definir siempre.
Append-only: Sólo pueden subir ficheros, pero no modificar ni borrar nada de lo que haya
Esta última es la que nos interesa. Si cambiamos nuestro acceso a append-only, ya puede entrar un intruso en nuestros sistemas, que no va a poder hacer nada destructivo con nuestros backups.
¿Hay algún inconveniente? Sí, que al no poder borrar nada en el backend, el gestor de backups tampoco puede hacer limpieza y borrar backups antiguos, con lo que podemos acabar con problemas de espacio. En el caso de BorgBase eso no es un problema, ya que tenemos dos opciones para esto:
Definir una clave SSH especial, con acceso completo, sólo para compactar de vez en cuando, y de vez en cuando compactar manualmente (aunque eso ya implica intervenciones manuales, algo no-bueno en políticas de backup)
Programar compactados periódicos del repositorio, desde el mismo BorgBase.
Está última opción es, de largo, la más práctica y segura, ya que funciona ella solita periódicamente, y a la vez no requiere definir claves SSH con acceso total, que hay que guardar y securizar en algún sitio, y pueden ser un problema. Aquí se ve la ventaja de usar un backend como BorgBase, altamente integrado con el propio gestor de backups (borg) y que es capaz de hacer tareas del propio gestor, a nivel de servidor. En caso de estar usando una solución más genérica como Backblaze B2, probablemente no nos quedaría otra que definir un acceso full en algún sitio, con los riesgos que conlleva.
Si securizamos de esta manera los accesos al backend de backups, quedamos totalmente protegidos contra un ataque ransomware, ya que por mucho que un intruso gane acceso a nuestros sistemas, y tenga todos los usuarios y contraseñas para acceder a nuestro servidor de copias, no va a poder hacer nada destructivo con ellas, con lo que el ataque pierde todo el sentido.
Conclusión
En definitiva, que securizar un poco nuestros sistemas de backup automático para hacerlos robustos frente a ataques de ransomware, no es nada complicado, y nos puede salvar de más de un disgusto. Que todos pensamos que lo nuestro es muy guay y seguro y que estas cosas sólo les pasan a los demás… hasta que pasa.
Como ya he contado otras veces, tengo montado un tinglado creo que bastante estándar: un montón de contenedores Docker con todotipo de servicios, con un servidor web por delante haciendo de proxy inverso, dirigiendo el tráfico hacia donde corresponda, en función de por qué URL hayan entrado. En mi caso, usaba Apache.
Pero conforme pasa el tiempo y cada vez tienes más cosas, este servidor web frontal se va complicando notablemente. Porque no es sólo redirigir el tráfico, hay casos concretos que tienen particularidades que hay que resolver (malditos websockets). Y también hay que añadir autenticación para no tenerlo todo expuesto, y por supuesto hoy en día o sales con HTTPS, o te arriesgas a que cualquier día tu web la tengan unos hackers turcos para usos poco edificantes.
Y no sé si es que Apache muestra ya su edad, o simplemente es potentísimo y te permite hacer cualquier cosa, pero el caso es que me encuentro haciendo un montón de cosas «a pelo», cuando tengo la sensación de que podrían ser un poco más automáticas. Tampoco ayuda que yo no soy un experto mundial en Apache, digamos que sé hacer lo básico y poco más, con lo que al final me paso el día googleando cómo hacer tal o cual cosa, y copiando y pegando directivas de StackOverflow o similar, llegando un punto en el que ni sé lo que estoy haciendo. Por no hablar de la de veces que acabo desistiendo, y por mucho que dirija y redirija, no hay manera de que el dichoso ProxyPass funcione como toca.
A esto se une que, cuando googleas sobre estos temas, te surgen otros nombres. NGINX, HAProxy, Traefik, Caddy… Vamos, que era hora de analizar si realmente no hay una forma mejor de hacer las cosas. NGINX lo medio conozco y me parece parecido a Apache en cuanto a potencia y gestión (con el rollo de tener que reaprender todo). HAProxy francamente lo descarté porque su página web parece hecha en el año 1997. Eso me dejó dos posibilidades:
Traefik: Muy buena pinta. Básicamente es implementar toda la configuración del servidor web como anotaciones en los contenedores Docker. Vamos, que no hay (apenas) configuración en sí. Simplemente, si quiero que tal contenedor esté expuesto al exterior, le añado unas anotaciones en el fichero de configuración de docker-compose, diciendo bajo qué dominio, etc., y toda la configuración se hace de forma transparente.
Caddy: Un servidor web más clásico, en el sentido de que sí es un programa externo, y sí tiene ficheros de configuración. Pero al mismo tiempo está pensado para ser muy simple, y gestionar automáticamente y por defecto cosas que en otro servidores web habría que hacer de forma explícita.
El que me atraía más era Traefik, porque eso de quitar de en medio toda la configuración y convertirla en simples anotaciones me parecía ideal. Ahora podría hacer un razonamiento muy sesudo de por qué finalmente lo descarté, pero el motivo fue muy sencillo: no fui capaz de hacerlo funcionar. Al principio es muy sencillo, pero conforme van apareciendo particularidades (por ejemplo Home Assistant que funciona en modo host), iba añadiendo más y más cositas por aquí y por allá, y para cuando me di cuenta tenía una configuración casi más compleja que la que tenía con Apache, y encima con cosas que todavía no funcionaban. Vamos, que tiré la toalla. No quiero decir que Traefik no esté bien, muy probablemente el problema esté en el hardware que hay entre la silla y pantalla (o sea, yo).
Vamos, que al final me decidí por Caddy. De entrada no muy motivado, porque el planteamiento de Traefik como que mola mucho, y Caddy parece más «clásico», pero la verdad es que se me pasó rápido. Es ponerse a hacer las cosas con Caddy, y la sensación es «¿Ya? ¿De verdad no hay que hacer nada más?». Es alucinante cómo en dos patadas tienes definido un tinglado que en Apache tiene telita. Como ejemplo un botón. Un servicio clásico en Apache sería una cosa así:
<IfModule mod_ssl.c>
<VirtualHost *:443>
ServerName hass.midominio.com
# Permitir acceso sin autenticación a manifest.json para poder añadir a pantalla de inicio en Android
<Location /manifest.json>
Order deny,allow
Allow from all
Satisfy any
</Location>
<Location /static/icons>
Order deny,allow
Allow from all
Satisfy any
</Location>
<Location />
AuthType Basic
AuthName "Cosas sensibles"
AuthBasicProvider file
AuthUserFile /etc/apache2/passwords
Require user miusuario
</Location>
ProxyPreserveHost On
ProxyRequests off
ProxyPass /api/websocket ws://localhost:8123/api/websocket disablereuse=on
ProxyPassReverse /api/websocket ws://localhost:8123/api/websocket
ProxyPass / http://localhost:8123/ disablereuse=on
ProxyPassReverse / http://localhost:8123/
ProxyPass /static/translations/ http://localhost:8123/static/translations/
ProxyPassReverse /static/translations/ http://localhost:8123/static/translations/
RewriteEngine on
RewriteCond %{HTTP:Upgrade} =websocket [NC]
RewriteRule /(.*) ws://localhost:8123/$1 [P,L]
RewriteCond %{HTTP:Upgrade} !=websocket [NC]
RewriteRule /(.*) http://localhost:8123/$1 [P,L]
LogLevel info
Include /etc/letsencrypt/options-ssl-apache.conf
SSLCertificateFile /etc/letsencrypt/live/backup.fkes.bid-0002/fullchain.pem
SSLCertificateKeyFile /etc/letsencrypt/live/backup.fkes.bid-0002/privkey.pem
</VirtualHost>
</IfModule>
Lo que viene a ser una cosa normal para servir un Home Assistant: le dices bajo qué dominio lo servirás, pones los Proxypass hacia la máquina/puerto que toque, ajustas los permisos sobre qué usuario hará falta para entrar, y luego toda una serie de magia negra para que el ProxyPass vaya bien en los diferentes casos (accesos normales, websockets, excepciones…). Finalmente la información sobre los certificados que tiene que usar para HTTPS. Y no he puesto otras cosas que van en otros ficheros, como la redirección de HTTP a HTTPS, o toda la gestión de pedir y renovar los certificados.
Y ya está, no hay más. Todas las pirulas para que el tráfico fluya no hay que hacerlas, la autenticación es una línea, y sobre certificados HTTPS no hay que hacer nada, porque el mismo Caddy gestiona este tema internamente de forma automática (si no le dices nada, sirve por HTTPS, gestionando él mismo la emisión y renovación de certificados con LetsEncrypt, añadiendo además la redirección automática de HTTP a HTTPS).
Vamos, que me he quedado a cuadros. En 5 minutos literales había migrado toda mi configuración de una veintena de ficheros de Apache a un único ficherín Caddy de menos de 100 líneas, con todo funcionando perfectamente (incluso cosas que con Apache fui incapaz de hacer andar). La sensación era que era todo demasiado bonito para ser verdad, y que algo fallaría y me obligaría a volver a Apache mientras buceo en foros a ver cómo arreglarlo, pero de momento todo funciona perfectamente, y encima mejor: por ejemplo, la pantalla para servir ficheros estáticos de Caddy le pega mil vueltas a la de Apache (es más bonita, incluye un filtro de búsqueda integrado…).
En definitiva, que igual un experto en Apache se lo pasa mejor teniendo el control total sobre todos los aspectos de la comunicación, pero en mi caso Caddy me ha solucionado muchísimo la vida. Está claro que vale la pena hacer un poco de prospección, cada 5-10 años o así, para ver cómo va evolucionando la tecnología, que a veces por inercia de usar lo de siempre, nos acabamos complicando la vida.
Hace mucho tiempo que quería tener una estación meteorológica, para saber en todo momento qué temperatura hay, si sopla el viento o si está lloviendo. Es algo muy útil para múltiples temas domóticos. Por ejemplo, sería fantástico que cuando se ponga a llover, o el viento supere un cierto umbral, me llegue un Telegram diciéndome que ojo, que está el tiempo revuelto, mira a ver si tienes todas las persianas cerradas y nada que se pueda mojar.
Pero te pones a rascar, y resulta que la mayoría de estos productos son notablemente cerrados: la mayoría sólo te muestra la información en alguna pantallita, o una aplicación de móvil como mucho. E incluso las que tienen un programa desde el que procesar la información, acostumbra a ser un programa propio, desde el que es difícil exportar la información a otras historias.
Pero un día me encontré un post en Reddit que explicaba algo muy interesante: resulta que la mayoría de estaciones meteorológicas que tienen una unidad exterior (con los sensores) y otra interior (pantallita con los datos) se comunican entre sí mediante una comunicación por radio, que se puede «interceptar» fácilmente con un pincho USB de 15 eur, y que luego, usando el software adecuado, se puede decodificar para extraer la información. Es una cosa que parece muy hacker, pero la verdad es que es todo muy sencillo de montar, y funciona de maravilla. Al lío entonces:
La estación
En lo que respecta a la estación meteorológica que escoger, obviamente hay que elegir una que sea «hackeable». Para eso lo más fácil es ir al final de la cadena, al software que decodifica la información, y ver qué modelos soporta. Yo elegí la Bresser 5in1, primero porque era la que se explicaba en el post de Reddit, pero también porque mide exactamente lo que yo quería (temperatura y humedad, viento y lluvia), y además tengo otros productos de la marca y me gusta.
Mide todo lo que quiero: temperatura, humedad, lluvia, dirección e intensidad del viento… La unidad interior es lo de menos, porque la vamos a hackear
La instalación del aparato ya es un tema aparte, pero en el fondo es sencillo: la unidad exterior se planta en un poste, y la unidad interior es una pantallita que muestra los datos de temperatura, viento, lluvia y demás. Los dos aparatos funcionan con pilas, que ya veremos lo que duran. Tengo en mente un hackeo extra para alimentar al menos la unidad exterior desde la red, porque tener que bajar el aparato del poste, aunque sea cada X meses, no deja de ser una molestia. Pero eso ya es carne para otro post.
El aparato para leer la señal
Una vez esté la estación meteorológica montada y funcionando, ya estamos en disposición de capturar la señal. Para eso lo que necesitamos es simplemente un stick USB sintonizador de TV, pero no uno cualquiera, sino uno con un chipset específico, en concreto un Realtek RTL2832.
Un stick USB para ver la TV, sólo que en este caso sólo lo usaremos para captar la señal de radio
Yo he comprado este, pero porque soy un ansias y lo quería ya. A mí me costó como 15 eur, pero si lo compras en China y no te importa esperar un mes, se puede conseguir por unos 5 euritos fácil.
Ojo, que es importante que venga con la típica antenita moñas, la típica que cuando quieres usar el stick para ver la TV no vale para nada. Para ver la TV no valdrá, pero para captar la señal de radio es ideal.
Siempre me indignaba con esta antena, porque no vale absolutamente para nada, pero resulta que para radio sí va bien
La instalación en cualquier linux moderno es trivial, no hay que hacer nada especial. Lo único es asegurarse que, al enchufar, se establezcan los permisos correctos. Para eso hay que añadir una línea como la siguiente en el fichero /etc/udev/rules.d/20.rtlsdr.rules:
Con esto, sólo hay que asegurarse de que nuestro usuario está en el grupo adm (sudo adduser usuario adm si no es así), y ya debería funcionar bien.
El software
Con la estación montada y el stick USB enchufado y configurado, ya sólo falta leer los datos. Para eso hace falta el comando rtl_433, que es el programa que coge la señal, la interpreta y busca patrones conocidos para decodificarlos. Soporta dispositivos a cascoporro, que se pueden consultar en su página web o desde la misma ayuda del programa.
La instalación del programa es trivial en cualquier linux moderno, ya que suele estar en los repositorios:
sudo apt-get install rtl_433
Y listos. Si lo ejecutamos tal cual, nos mostrará esto:
usuario@maquina:~$ rtl_433
rtl_433 version 20.11-43-g61d24ba9 branch master at 202101281106 inputs file rtl_tcp RTL-SDR
Use -h for usage help and see https://triq.org/ for documentation.
Trying conf file at "rtl_433.conf"…
Trying conf file at "/home/pi/.config/rtl_433/rtl_433.conf"…
Trying conf file at "/usr/local/etc/rtl_433/rtl_433.conf"…
Trying conf file at "/etc/rtl_433/rtl_433.conf"…
Registered 147 out of 177 device decoding protocols [ 1-4 8 11-12 15-17 19-21 23 25-26 29-36 38-60 63 67-71 73-100 102-105 108-116 119 121 124-128 130-149 151-161 163-168 170-175 177 ]
Detached kernel driver
Found Rafael Micro R820T tuner
Exact sample rate is: 250000.000414 Hz
[R82XX] PLL not locked!
Sample rate set to 250000 S/s.
Tuner gain set to Auto.
Tuned to 433.920MHz.
Allocating 15 zero-copy buffers
Aquí se ve como detecta el stick, y empieza a escanear. Pero aquí no encuentra nada, porque probablemente la frecuencia que usa por defecto no es la de nuestro aparato, y además no es muy eficiente porque está escaneando 177 protocolos distintos a la vez, cuando bastaría que buscase el de nuestro aparato (a no ser que queramos hackear la estación del vecino, que también es una opción 🙂 ). En mi caso, el comando mágico para mi estación es el siguiente:
usuario@maquina:~$ rtl_433 -f 868300000 -R 119 -Y classic -C si
rtl_433 version 20.11-43-g61d24ba9 branch master at 202101281106 inputs file rtl_tcp RTL-SDR
Use -h for usage help and see https://triq.org/ for documentation.
Trying conf file at "rtl_433.conf"…
Trying conf file at "/home/pi/.config/rtl_433/rtl_433.conf"…
Trying conf file at "/usr/local/etc/rtl_433/rtl_433.conf"…
Trying conf file at "/etc/rtl_433/rtl_433.conf"…
New defaults active, use "-Y classic -s 250k" for the old defaults!
Registered 1 out of 177 device decoding protocols [ 119 ]
Detached kernel driver
Found Rafael Micro R820T tuner
Exact sample rate is: 1000000.026491 Hz
[R82XX] PLL not locked!
Sample rate set to 1000000 S/s.
Tuner gain set to Auto.
Tuned to 868.300MHz.
Allocating 15 zero-copy buffers
time : 2021-01-30 17:16:21
model : Bresser-5in1 id : 106
Battery : 1 Temperature: 17.2 C Humidity : 63 Wind Gust : 2.0 m/s
Wind Speed: 2.3 m/s Direction : 202.5 Rain : 29.2 mm Integrity : CHECKSUM
time : 2021-01-30 17:16:57
model : Bresser-5in1 id : 106
Battery : 1 Temperature: 17.2 C Humidity : 64 Wind Gust : 4.0 m/s
Wind Speed: 2.4 m/s Direction : 157.5 Rain : 29.2 mm Integrity : CHECKSUM
Aquí ya hemos restringido la búsqueda sólo al protocolo de nuestra estación, y hemos establecido la frecuencia que toca (que al final es la que pone en las especificaciones del aparato). Así ya vemos que empieza a encontrar información, y por defecto las muestra por pantalla.
Pero esto no es todo, la gracia de rtl_433 es que tiene un montón de formas de procesar la información que decodifica. Y como sólo ver por pantalla los datos tampoco es demasiado útil, lo suyo es sacarlos de otra manera. Y en un contexto domótico, lo mejor es exportar la información por MQTT, porque así es directamente integrable en cualquier otra plataforma, ya sea Home Assistant, NodeRED, o lo que sea. En mi caso, se le añade un parámetro al comando:
Obviamente hay que tener un servidor MQTT montado, pero vamos, montarse un mosquitto son 5 minutos.
Ya para rematar la cuestión, si lo que queremos es dejar esto funcionando las 24h, lo suyo es añadir este comando como un servicio que se arranque automáticamente al inicio de la máquina. Para esto se puede crear un servicio systemd creando un fichero /etc/systemd/system/rtl_433.service con el contenido:
Con todo montado, ya podemos leer los datos desde cualquier plataforma que soporte MQTT (y la que no lo soporte no merece existir), y hacer lo que queramos con los datos. Yo por ejemplo de momento me dibujo cuatro gráficas con Grafana:
Como remate final, en mi caso si ponía el stick USB donde tengo el servidor, no me llegaba bien la señal, por lo que pasé todo el sistema a una Raspberry Pi, para poder ponerla más cerca de la estación exterior. El proceso viene a ser el mismo, la única diferencia es que el comando rtl_433 no está en los repositorios, y hay que compilarlo a mano. Siguiendo las instrucciones es muy sencillo.
Me preocupaba que una Raspberry Pi no tuviera potencia para decodificar la señal, pero teniendo en cuenta que uso la Raspberry Pi Zero, que es la menos potente de la familia, veo que la CPU se queda en un 50%, por lo que va más que sobrada. Si se usa cualquier ordenador normal el consumo de CPU es totalmente irrisorio, en mi servidor no llegaba al 2%, y eso que tiene un Celeron fanless de bajo consumo.
A partir de aquí, a hacer automatizaciones se ha dicho. Tampoco está de más, ya que lo tenemos todo montado, subir nuestros datos a MeteoClimatic y compartirlos con quien los pueda necesitar, pero eso lo dejo para otro post.
El microondas es de esos electrodomésticos que parece atemporal, porque en el fondo el funcionamiento es más simple que el mecanismo de un chupete: abro microondas, pongo la taza de leche, 30 segundos y palante. Además son aparatos que suelen durar eones, son incombustibles. Pero en casa recientemente se nos fastidió el microondas (en realidad la rueda, calentar sigue calentando bien) y me puse a investigar el tema. Y mire usted por dónde, que parece que sí se han hecho avances en los últimos 20 años.
Inverter
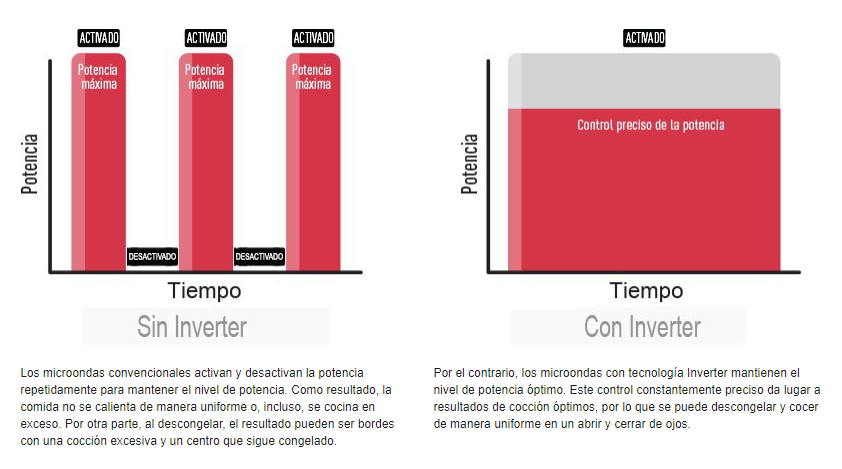
El avance que veo más relevante, es que ahora hay un par de marcas que venden microondas con tecnología Inverter. ¿Mande? ¿Eso qué es? Pues aunque parezca un palabro de márqueting, en realidad es el mismo concepto de los aires acondicionados: el aparato, en vez de dar siempre toda la potencia, puede graduarse a cualquier nivel de intensidad. De esa forma, se ajusta siempre a la potencia necesaria, y se ahorra energía.
Buah, alguno dirá, mi microondas de hace 20 años ya permite graduar la potencia, eso del inverter es un sacacuartos. Pues no, porque resulta que eso de graduar la potencia de los microondas «clásicos» es un poco timo de la estampita, porque el microondas sigue calentando a tope de potencia, pero a intervalos intermitentes para que, en promedio, la potencia global sea baja. Esa es la causa de que, por ejemplo, al descongelar se chamusque la comida por fuera, y quede como un témpano por dentro. Con un Inverter, si le pongo potencia baja, realmente pondrá potencia baja todo el rato, con lo que el resultado es mejor. Esta gráfica que he fusilado descaradamente de la web de Panasonic ilustra bastante bien la diferencia entre un microondas clásico y un Inverter:
Actualmente, sólo hay dos marcas que tengan microondas Inverter, LG y Panasonic. Supongo que se irán subiendo al carro las demás, pero estos parece que son los que han inventado el tema.
Sensores
Otra cosa que me ha llamado la atención de los microondas de hoy en día, es que algunos incluyen sensores que permiten hacer cosas medio inteligentes. Por ejemplo, los Panasonic tienen un sensor de humedad, que permiten calentar algo sin indicarle el tiempo: se le pone una tapa que tenga algún agujerillo (en el manual pone poner papel film agujereado, pero me niego), y el microondas detecta el vapor que sale cuando ya se ha calentado el plato, y para. Los LG permiten, una vez ha acabado el ciclo de calentamiento, mantener el plato caliente, usando el mismo método.
La verdad es que es una buena idea, y es cómodo.
Tamaño
Un tema bastante prosaico, y que supongo que no es nuevo, pero yo no había visto hasta ahora: no todos los microondas son canijos, los hay de diferentes tamaños. Bueno, básicamente hay como dos medidas medio estándar: el normal de toda la vida, de unos 22-24 litros, y uno un poco más grande, de 31-32 litros. Eso repercute en el diámetro del plato interior, que puede ser de hasta 36 cm respecto a los 25-27 de los pequeños, y que permite poder calentar no sólo platos, sino también fuentes y tuppers grandes.
Parece una tontería, pero cuando tienes que calentar los macarrones de ayer para que coman 4 personas, se agradece poder hacerlo todo de una vez en vez de plato a plato. Por no hablar de que las cosas se calientan mejor y más uniformemente en una fuente grande, bien distribuidas, que apelotonadas en un recipiente pequeño.
Algunas cosas no cambian nunca
Eso sí, algunos aspectos «clásicos» de los microondas sí que observo que no han cambiado. Por ejemplo la cantidad de modos absurdos e inútiles que tienen. El que me he comprado viene hasta con un libro de recetas para hacer todo tipo de platos, desde una Vichyssoise hasta un ganso al horno. Seamos realistas, el microondas no es un artilugio adecuado para cocinar platos mínimamente complejos: es complicado que caliente uniformemente, no dora los alimentos como toca, y la comida hecha al microondas no queda nada apetecible. Al final, el 90% de usos del microondas son para calentar la leche por la mañana, o los macarrones de ayer que quedaron en la nevera. Luego hay cosas que al microondas quedan bien, como las verduras al vapor, o quizá algún flan, pero son más excepciones que otra cosa. Y los fabricantes siguen erre que erre complicando los controles con modos estrambóticos para asar carne o hacer una sopa, que nadie va a usar jamás.
Y esa es otra, los controles. Con tanto complicarse la vida con modos exóticos que nunca vas a usar, al final resulta que hacer lo básico es dificilísimo. Estoy harto de ir a casa de familiares y conocidos, querer calentar algo unos segundos en el microondas, y tener que pedir ayuda, porque no hay quien se aclare con qué botón hay que usar. O que esté claro, pero los controles estén optimizados para los casos absurdos de cocinar un faisán con grosellas y no para el uso real del día a día. Por ejemplo:
Buena suerte poniendo 20 segundos de tiempo en este microondas, hay que tener pulso de neurocirujano
Parece mentira, pero cuesta horrores encontrar un microondas en el que los casos comunes se configuren fácilmente.
Pero, yo sólo quería calentar la leche…
Otro tema que encuentro absurdo es la manía de ponerle grill al microondas. ¿Qué sentido tiene usar un grill canijo, birrioso y lento, cuando casi seguro tienes a menos de un metro un horno con un grill de verdad? Pues erre que erre con el grill, que además, como se usa poco, cuando lo enciendes empieza a oler a pollo quemado que echa para atrás. Y que no falten la ristra de accesorios para usar con el birria grill, que pasarán de la caja al fondo del armario de la cocina, y de ahí unos años después a la basura cuando nos preguntemos para qué narices debe ser esta rejilla extraña que ha aparecido por aquí junto con el pie de repuesto del árbol de navidad.
Pero bueno, no todo es tan terrible. Reconozco que algunos de los programas que vienen con el microondas que me he comprado son medio útiles. Por ejemplo, hay uno que permite descongelar el pan indicándole sólo el peso, sin decirle tiempo ni nada. Y él mismo te avisa a medio programa de que le des la vuelta a la barra. Reconozco que ese igual hasta lo uso.
Mis recomendaciones
Como he investigado un poco el tema, pues pongo aquí también mis conclusiones por si a alguien le sirven. Yo tenía claro que quería un microondas grandote, y que fuera Inverter. Como he dicho antes, de esos sólo hay de dos marcas:
Panasonic: Aunque el modelo actual es el NN-GT45K, yo me he comprado el anterior, ya medio descatalogado, el NN-GD462 (o NN-GD452 en versión blanca en vez de plateada). ¿Por qué? Pues porque en el actual todo se hace con botones, y el modelo anterior tiene una rueda, que la encuentro más práctica. Pero las especificaciones son idénticas, es el típico caso de fabricante que saca modelo nuevo cada año cambiando dos minucias estéticas. La versión de tamaño normal es la NN-GD34H.
LG: Estos no me los he comprado porque eran un pelín más grandes que los Panasonic y no me cabían, pero se ven también muy bien. Está el MH7265, que es el grande, y el de tamaño normal es el MH6535. Las especificaciones son muy parecidas a los Panasonic en cuanto a sensores y compañía.
Llevamos un tiempo en casa intentando reducir el uso de plásticos y ser más sostenibles en general, y un día caí en que gran parte de los envases que generamos son yogures. En casa somos 4, y consumimos yogures a un ritmo galopante (hay ciertos señores bajitos que se los zampan de 2 en 2 o de 3 en 3). Nunca había visto que eso tuviera solución, hasta que una amiga me enseñó que se hacía sus propios yogures (además buenísimos), y ahí una neurona me hizo clic.
El caso es que ahí empecé a investigar el tema, y fui haciendo experimentos.
Primera iteración: versión «estándar»
De entrada la cosa es fácil: mezclas un yogur normal con 1 litro de leche, lo dejas reposar como 8 horas o así a unos 40 ºC y listos, ya tienes yogur. Como no tengo yogurtera, y paso de meter otro cacharro en casa, lo hice en el horno, que tiene un modo de descongelación en el que le puedes ajustar la temperatura a valores muy bajos. 8 horas a 41 ºC, y los yogures salen sin problema.
¿Problemas? Varios:
La consistencia no es tan firme como la de los yogures normales, salen algo más líquidos
Para mi gusto, quedan algo ácidos
Hay que seguir comprando yogures, para usarlos de «semilla»
Aparentemente la cosa no es muy boyante, parece que hay más inconvenientes que ventajas. Afortunadamente no desistí, y empecé a leer sobre el tema. Dejando de lado que muchos blogs que hablan del tema son un tanto, ejem, comeflores y dicen cosas un poco estrambóticas, como que es mejor leche normal que pasteurizada (cuando es al revés, la leche natural tiene más bichillos, que compiten con el yogur por la lactosa) sí descubrí cosas muy interesantes. Como que en vez de partir de un yogur comprado se puede comprar directamente el bacilo de los yogures, desecado, con lo que consigues yogures «de pura raza», más firmes y consistentes. O que no hay un único bacilo para hacer yogur, sino que hay varios para diferentes gustos. Además de varios truquillos para mejorar la consistencia.
Así las cosas, a continuación viene la…
Iteración final: los yogures perfectos
En mi experiencia de prueba y error, para conseguir unos yogures perfectos, hace falta:
Lactobacilus bulgaricus, o sea yogur búlgaro. Es un tipo de yogur menos ácido y más cremoso que el normal que comemos por aquí, y para yogures caseros es ideal. Yo lo encontré en Amazon.
Obviamente, botes en los que poner el yogur. Ya que estamos reduciendo plástico, de cristal. Y con tapa, o si no habrá que empezar a tapar con papel film y demás, y no habremos ganado nada en cuanto a reducción de plásticos. Yo uso éstos, son perfectos tanto en tamaño como en funcionalidad.
1 litro de leche semidesnatada (empecé con entera, pero quedan igual de bien y así son menos grasos)
2 cucharadas de leche en polvo desnatada (aporta lactosa, por lo que mejora la consistencia sin añadir grasas)
Azúcar al gusto y, si apetece, colorantes o saborizantes diversos: yo he probado de vainilla, limón, naranja, fresa, coco, plátano y tarta de queso. Todos muy buenos, incluso diría que con mejor gusto que los clásicos de los yogures de supermercado. Incluso algunos (como el de naranja) que directamente no existen en yogures comprados.
Un termómetro de cocina como éste ayuda mucho en las diferentes fases
Lo que hay que hacer es poner la leche al fuego junto con el azúcar (opcional) y la leche en polvo, y cuando llegue a unos 75 ºC, bajar el fuego y mantenerla ahí 10 minutos. Luego retirar, dejarla templar hasta que llegue a 40 ºC, y añadir el sobrecito de lactobacilo. Remover bien con unas varillas, añadir saborizantes o colorantes si se quiere, y poner en los botes. Dejar unas 24h a entre 40 y 45 ºC, y listos.
La gracia de usar lactobacilo es que la primera remesa se puede usar para hacer una segunda, con la diferencia de que en vez del sobrecito hay que poner 50 g del yogur de 1ª generación, y que en vez de 24h basta con 6h o así. Por supuesto la primera generación se puede comer también sin problema, faltaría más, sólo que es una pena que, con lo que tarda la primera vez, no la guardemos para facilitar las siguientes remesas. Por no hablar de que así «exprimimos» más los sobrecitos, como se verá a continuación.
Economía del proceso
A ver, que este blog es de eficiencia, no de cocina. Hacer yogures está muy bien, pero no podemos dejar de analizar el aspecto económico y monetario del asunto.
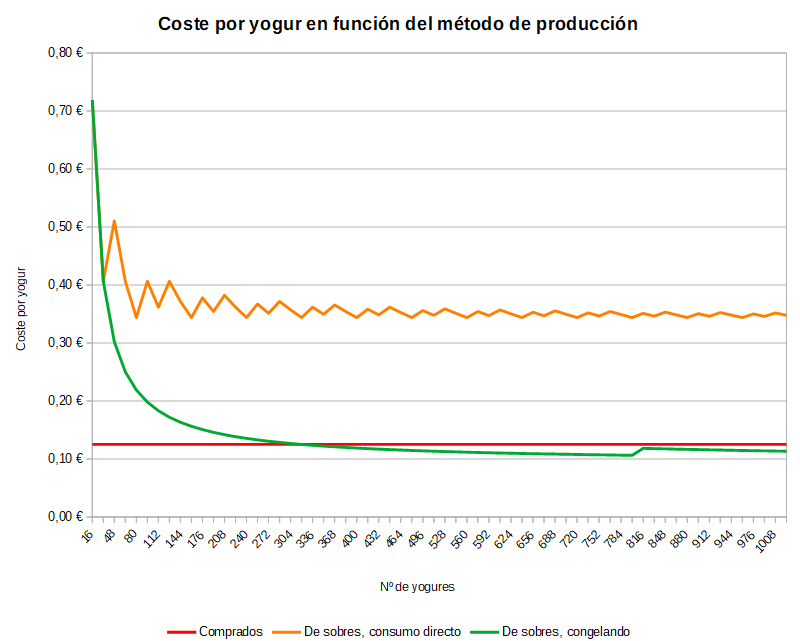
Veamos, en el súper, un pack de 16 yogures Hacendado (en mi opinión los más buenos del mundo mundial) sale a 2 eurillos. Eso son 12,5 céntimos el yogur.
El preparado para yogures sale por unos 10 eur, y tiene 5 sobres. Si con cada sobre y 1 litro de leche hago 8 yogures, me sale que 40 yogures me han salido por 13,75 eur (10 eur del preparado + 5*0,75 eur de la leche), o sea 34 céntimos el yogur. Vaya por $DIOS, sale a más del triple…
Pero no seamos tan obtusos, porque la primera generación del yogur la podemos usar para hacer las siguientes. Si somos previsores y el yogur «de polvitos» lo congelamos entero, y tenemos en cuenta que una tongada de 8 yogures requiere sólo 50 g de yogur, resulta que cada sobrecito me da para 20 «dosis» de 50 g, o sea 200 yogures. Por tanto, con la caja entera serían 800 yogures en total. Para tanto yogur necesitaré 105 litros de leche, por lo que me habré gastado 88,75 eur, o sea algo más de 11 céntimos el yogur.
Así parece que ya nos salen las cuentas. Pero veamos cómo va variando el coste por yogur en función de cuántos yogures hagamos:
Para los yogures comprados, está claro: valen lo mismo independientemente de cuántos te comas.
Con los yogures caseros, se ve cómo al principio el coste es carísimo (por el hecho de que hay que comprar la caja con los fermentos, que son 10 euracos), pero conforme vas haciendo, los costes bajan notablemente. Si directamente usas los sobrecitos para hacer yogures y comértelos, el coste baja y se estabiliza, pero aún sigue siendo carísimo comparado con los yogures comprados. Ahora bien, si somos un poco listos y la primera tongada de los sobres la congelamos, el coste cae en picado, y para cuando llevamos como un tercio de los sobres gastados, ya estamos ahorrando dinero respecto a los yogures comprados. Aunque cuando pasamos el límite de los 800 yogures el coste vuelve a subir (porque toca comprar otra caja de polvos), la cosa se va estabilizando, y cuando el número de yogures tiende a infinito, el precio se estabiliza en poco más de 10 céntimos, casi 3 céntimos menos por yogur que los yogures comprados.
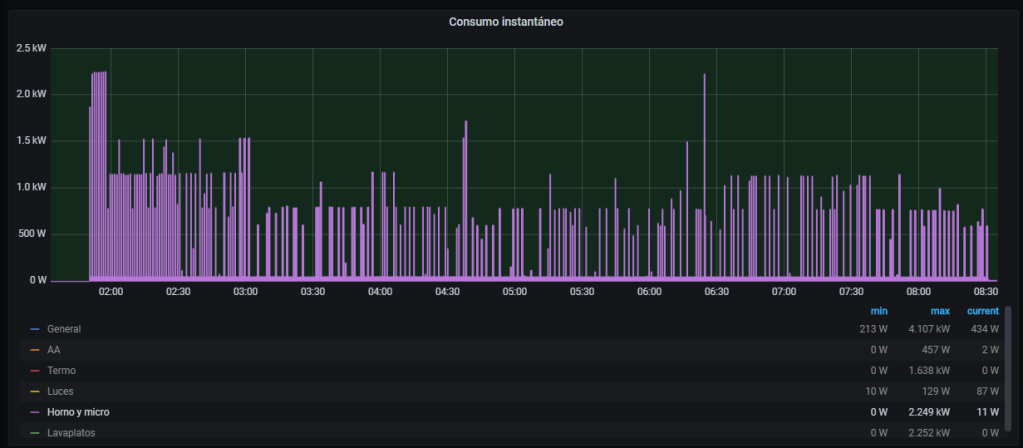
EDITO: Como muy bien comentan en los comentarios, no he tenido en cuenta el coste de la electricidad, porque quieras que no toda la noche en el horno a 40 ºC algo gasta también. Me he entretenido a mirar el consumo eléctrico del horno en una tongada de yogures, y me ha salido esto:
Consumo del horno durante toda la noche, para hacer una tongada de yogures
En total, he gastado 1,33 kWh, que en horario reducido me habrán costado unos 10 céntimos. Si he hecho 12 yogures, pongamos que el coste se incrementa en menos de un céntimo por yogur. Sigue saliendo beneficioso respecto a los comprados.
Por tanto, parece claro que, desde el punto de vista económico, los números salen por poco que planifiquemos bien. El beneficio medioambiental también es alucinante, porque con los yogures caseros generaremos cero patatero en cuanto a envases. Y el beneficio al paladar también es notable, porque francamente los yogures caseros están muy ricos. Tampoco olvidemos el aspecto saludable, porque en mi caso los yogures están igual o más ricos que los comprados, y con la báscula en la mano tienen más o menos la mitad de azúcar que los del súper.
Vamos, que lo de hacerse los yogures en casa sólo son ventajas: ahorraremos dinero, reduciremos plásticos, comeremos más sano y encima seremos la envidia de amigos y familia, cuando vean los yogures tan buenos que comemos 🙂
Bueno, en la entrada anterior contaba lo súper fantabuloso que es el Shelly EM como medidor de consumo energético, lo abierto que es y lo fácil que es integrarlo con casi cualquier cosa. Pues ahora falta ver la otra parte: cómo podemos coger los datos de consumo, y visualizarlos de forma bonita y vistosa.
Veamos, esta va a ser una entrada densa, porque hay que introducir muchos conceptos y hay muchas piezas interconectadas. Aunque pueda parecer todo muy complejo, en el fondo no es tan difícil, y la gracia es que, una vez montado el tinglado inicial, luego ir añadiendo cosas es trivial.
Pero al lío. Para poder llegar a ver gráficas chulas, hay que pasar por todas las fases:
Tener un medidor de consumo que nos dé los datos en un formato abierto y procesable: Chachi, eso ya lo tenemos, partiré de que tenemos un Shelly EM publicando los datos por HTTP o MQTT. Obviamente, cualquier otro medidor que proporcione los datos por una vía equivalente es igual de válido.
Ahora hay que recibir los datos de alguna manera. Lo más chulo y versátil para estas cosas domóticas es usar Node-RED (luego más).
Los datos hay que almacenarlos en alguna parte. Podríamos usar cualquier base de datos en plan MySQL, ficheros de texto o lo que sea, pero teniendo en cuenta que este tipo de datos crecen una barbaridad, lo más apropiado es usar una base de datos específica para guardar series temporales, como InfluxDB.
Y ahora que ya tenemos los datos guardaditos, ya podemos hacer gráficas, en este caso con Grafana.
Madre del amor hermoso, menuda movida para ver cuatro gráficas. ¿De verdad vale la pena? ¿No sería más feliz viendo las gráficas en el típico cacharrín propietario mientras dure su app? Afortunadamente, instalar todo esto es 1.000 veces más fácil que si lo hiciéramos a pelo, gracias a…
Docker
¿Ein? ¿No hablábamos de medir energía, de domótica y de instalar programas? Pues ahí andamos, porque resulta que Docker es una forma de instalar en dos patadas programas que serían tremendamente complicados de instalar si se hiciera a pelo.
El concepto de los contenedores Docker reconozco que es espinoso. Para el que esté familiarizado con el concepto de máquina virtual, se podría decir que un contenedor Docker es una especie de máquina virtual, pero «aligerada». Porque si una máquina virtual viene a ser un «miniordenador», con un sistema operativo entero y las aplicaciones que hagan falta, un contenedor Docker vendría a ser el resultado de «podar» esta máquina virtual y dejarla estrictamente con lo que necesita para ejecutar una aplicación concreta. Por eso con las máquinas virtuales hablamos de sistemas operativos (una máquina virtual con Ubuntu, o con Windows) pero con contenedores hablamos de aplicaciones (un contenedor con MySQL, o con Transmission).
La gracia extra de los contenedores es que, a diferencia de las máquinas virtuales, para las que se reserva una porción de memoria y unas cuantas CPUs, los contenedores se ejecutan todos sobre la misma máquina, compartiendo kernel, memoria y recursos. La argucia técnica que permite hacer eso aislando al mismo tiempo unos contenedores de otros lo dejo para otro día, pero el caso es que esta diferencia hace que arrancar o parar contenedores sea rapidísimo, comparado con una máquina virtual.
Otra ventaja de los contenedores es que tenemos dos cosas:
Un repositorio en internet (Docker Hub) de contenedores ya hechos, para casi cualquier aplicación que se nos ocurra.
Herramientas para orquestar el arranque de varios contenedores enchufados entre ellos, simplemente escribiendo un ficherito de texto.
O sea, que al final es raro que hagamos contenedores a pelo. Más bien cogeremos contenedores ya hechos, con los programas que nos interesen, y los configuraremos e interconectaremos para conseguir lo que queramos.
Como esto es muy teórico, se ve mucho mejor con un ejemplo. Pongamos que quiero montarme un blog con WordPress. Tradicionalmente, empezaríamos a instalar todos los requisitos: que si un Apache, que si el soporte de PHP, una base de datos MySQL… Y luego ponte a configurar todo.
Usando contenedores, bastaría crear un ficherito llamado docker-compose.yaml, tal que asín:
Con esto le estoy diciendo que quiero dos contenedores, uno con una BD MySQL, y otro con un WordPress. Y luego para cada uno configuro cuatro cosas: que si usuarios/passwords de la BD, que si en qué puerto servirá… El caso es que, una vez tengo esto, basta ejecutar:
docker-compose up
Y él solo ya se encargaría de bajarse los contenedores que le he indicado (wordpress y MySQL), configurarlos según mis instrucciones y ejecutarlos, con lo que ya puedo abrir el navegador, apuntar al puerto que corresponda, y ya tengo mi WordPress en marcha.
Chachi, ¿no? Pues después de la introducción, vamos a utilizar esto mismo para montarnos en dos patadas nuestro tinglado domótico.
Primer paso: Node-RED
Node-RED es… una cosa difícil de describir. Se podría decir que es una plataforma para interconectar diferentes sistemas de forma visual, a base de unir cajitas con líneas. Es una descripción poco científica, pero de verdad que es más fácil verlo y probarlo que intentar describirlo con palabras.
En nuestro caso, lo vamos a usar para coger lo que nos envíe el medidor de consumo, y enviarlo a nuestra base de datos.
Como hemos dicho, vamos a montarlo todo con Docker. Nos vamos a cualquier directorio, y editamos el fichero docker-compose.yaml, con el siguiente contenido:
Con esto le estamos diciendo que queremos un Node-RED en el puerto 1880, que queremos que guarde los datos en el subdirectorio data, y luego le hemos añadido un par de cosas para que tenga bien los permisos de los ficheros, coja bien la hora y esté siempre arrancado aunque reiniciemos el servidor.
Y ya está. Ejecutamos «docker-compose up», y ya deberíamos tener Node-RED en marcha.
Como la idea de Node-RED es enganchar el medidor con la base de datos, vamos a instalar esta última antes de configurar nada.
InfluxDB
InfluxDB es una base de datos como tantas, pero con una particularidad: está optimizada para guardar series temporales. ¿Qué quiere decir eso? Pues que si una base de datos normal guarda todos los datos en un registro de tamaño fijo, y tenemos muchos datos, eso va a ocupar un montón con el tiempo. Lo que hace InfluxDB es guardar las diferencias entre un dato y otro, de una forma muy compacta, de manera que lo que en otra base de datos ocuparía GB, aquí ocupa MB. Ideal para nuestro caso de guardar consumos eléctricos ad-infinitum.
Para instalarlo, volvemos a abrir el docker-compose.yaml, y añadimos un servicio nuevo, para InfluxDB:
Y ya está. Sólo le hemos indicado el nombre de la base de datos («energia») y hemos indicado que cree dos cuentas de usuario: una para administrar, y otra sólo con permisos de escritura, que será la que usemos para cargar los consumos.
Si volvemos a ejecutar docker-compose, veremos cómo se descarga y arranca la BD.
Enviar consumos a InfluxDB con Node-RED
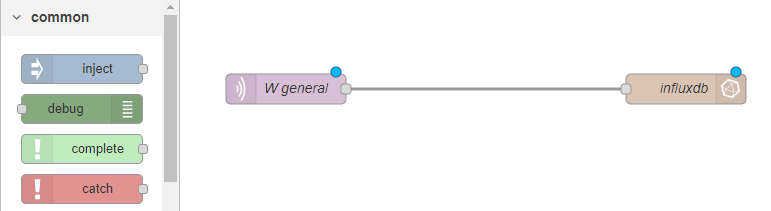
Ahora que ya tenemos la BD en marcha, vamos a usar Node-RED para leer los consumos del medidor, y enviarlos a InfluxDB. Para esto abrimos Node-RED, y tenemos que añadir dos nodos al tablero: uno para leer del medidor, y otro para escribir en InfluxDB. Los unimos con una flechita, y listos:
Hay que clicar en cada uno de los nodos, y configurar ahí lo que haga falta.
En el caso del medidor, yo leo los valores por MQTT, por lo que habría que indicar a qué «topic» escribe el medidor. Si se quisiera hacer por HTTP, habría que usar otro tipo de nodo, e indicar la URL y la frecuencia de lectura. Es un poco más complicado, sería algo así:
En vez de esperar a que llegue el valor, al leerlo por una web hay que leer periódicament (nodo timestamp, configurado para leer cada 10 segundos o así), luego hacer la petición (nodo http request) y luego, de entre todo lo que nos llega, sacar el consumo en W (nodo tipo Change, cogiendo el valor «power»).
En el caso del nodo de influxdb, hay que indicar el host y el puerto en los que tenemos la base de datos (son los valores que hemos indicado en docker-compose.yaml), así como el usuario y contraseña definidos antes.
Con esto ya tenemos los consumos eléctricos guardados en nuestra base de datos. Ahora sólo queda hacer gráficas.
Grafana
Grafana es una aplicación web para hacer gráficas chulas en tiempo real. Permite recuperar los datos de un montón de fuentes diferentes, entre ellas InfluxDB. Para añadir una instancia de Grafana a nuestro Docker, simplemente habría que añadir un servicio más a nuestro docker-compose.yaml:
Que viene a ser más de lo mismo que ya hemos visto: cuatro configuraciones sobre usuarios y compañía, puertos y directorio donde ser guardarán los datos. Aquí hay un par de cosas adicionales que no son imprescindibles: unos cuantos plugins extras que no vienen de serie, y un par de configuraciones en las que le indico un dominio, para poder acceder a la instancia de Grafana desde fuera de mi red local. Pero vamos, que no hacen falta.
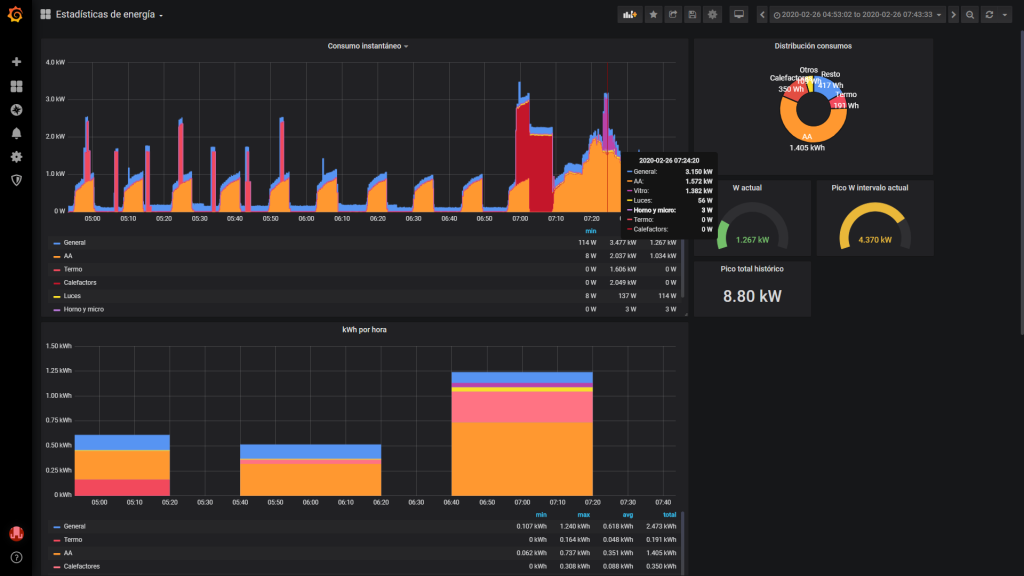
Con esto arrancamos Grafana, y ya podríamos configurar un datasource de tipo InfluxDB e ir añadiendo gráficas con lo que nos apetezca. En esto no voy a entrar porque esta entrada ya queda demasiado larga, hay guías a patadas sobre cómo usar Grafana, cada cuál tiene sus gustos y en el fondo el interfaz es muy intuitivo y amigable. Sólo pongo un pantallazo de cómo queda mi configuración de monitorización de energía:
Mi dashboard en Grafana
Chulo, ¿verdad? Y actualizado en tiempo real y totalmente interactivo para cambiar el intervalo de tiempo a analizar, hacer zoom o quitar o poner medidas. Bueno, en mi caso es un poco trampa, porque no tengo un solo Shelly EM, sino dos, midiendo cuatro circuitos, más un Shelly 1PM para medir las luces, más dos Shelly Plug S para medir los calefactores del baño, más un TP-Link HS-110 (este no es tan abierto como los Shellys, pero se puede usar con Node-RED Home Assistant mediante) para medir el termo… Si es que esto de ponerse a monitorizar es empezar, y no querer parar 🙂
En definitiva, que en dos patadas y gracias a Docker nos hemos montado un tinglado considerable, muy fácil de instalar y mantener. ¿Que mañana cambiamos el servidor? Pues cogemos el docker-compose.yaml, lo copiamos al nuevo, y con un docker-compose up lo tenemos todo de nuevo en marcha en segundos. Así da gusto instalar cosas.
Después de muchocacharrear con diversos monitores de energía y sus interfaces cerradas, creo que por fin he encontrado el medidor de energía definitivo. Es el Shelly EM, de la empresa búlgara Allterco (todo un descubrimiento, su catálogo no tiene desperdicio).
Es el típico medidor de energía por pinza amperimétrica, vamos, que no hay que hacer ningún empalme en ningún sitio, sino que simplemente pones una pinza al cable que quieras medir, y listos. En el caso del Shelly EM, de serie soporta 2 pinzas amperimétricas.
La comunicación con el resto del mundo es por Wifi, con lo que la instalación es la típica en estos dispositivos: de entrada te crea una wifi propia en la que entras y configuras todo, y a partir de ahí se conecta a la wifi de casa para enviar los consumos, actualizar el firmware y demás.
¿Por qué me gusta tanto? Pues porque, acostumbrado a los típicos aparatos que miden muy bien, sí, pero sólo puedes consultar los consumos desde su app o su nube, este Shelly EM (y en general todos los productos de la marca) es tremendamente abierto y agnóstico. Por supuesto puedes acceder desde su app, pero si no quieres atarte a nadie, consultar el consumo es tan fácil como meterte en cualquier navegador y consultar una URL en plan:
http://mimedidorshellyem/emeter/1
(Obviamente poniendo la IP del cacharrín en vez de «mimedidorshellyem»). Eso nos devolvería algo como esto:
Que en términos informáticos es una representación JSON de lo que esté midiendo el monitor (potencia, voltaje, reactiva, etc.). El JSON es algo que «entiende» prácticamente cualquier programa o sistema domótico, con lo que la integración con prácticamente cualquier cosa es trivial.
¿Que consultar por HTTP es muy pedestre? Pues el Shelly EM también soporta enviar los datos vía MQTT, un protocolo muy apañado y totalmente abierto que permite integrarlo también con lo que sea.
¿Que aún así no nos parece lo bastante abierto y queremos instalarle un firmware alternativo? Pues no sólo es posible, sino que los señores de Allterco hasta nos han dejado el puerto a la vista para flashearlo según nos parezca y ponerle algo como Tasmota o ESPurna.
El puerto para flashear está bien a la vista, todo un detalle
En definitiva, que todo un gustazo encontrarse algo así de abierto y fácil de integrar con cualquier cosa, y encima a precio de derribo. Me estoy volviendo muy fan de esta marca, porque la verdad es que tiene otros productos también fantásticos…
Ahora en próximas entradas veremos cómo integrar los datos que nos da el medidor para montarnos unas gráficas bien chulas de forma sencilla.
Hace unos meses escribí una entrada explicando cómo irnos de Dropbox y montarnos un Nextcloud por nuestra cuenta. Es gracioso, porque acababa la entrada diciendo:
[…]es fácil que acabe volviendo a Dropbox cuando se bajen del burro y ofrezcan un plan familiar decente, o al menos más granular que el actual (300 GB por 3 eur/mes, por ejemplo, sería fabuloso).
Pues después del currazo, resulta que casi casi estamos allí :-).
Que no es que Dropbox haya bajado precios de repente, pero vamos, que lo que he encontrado se acerca bastante a lo que quería. Resulta que, aprovechando que Nextcloud es libre como el sol cuando amanece, hay hostings por ahí dando servicio, con diferentes ofertas. Y el otro día, en los comentarios de Reddit de una noticia, encontré Hetzner, que aunque tiene un nombre un pelín impronunciable, es una empresa de hostings que tiene unos planes de pago de hostings Nextcloud muy, muy apetecibles. El más básico son 3 euritos al mes, que te dan 100 GB de espacio, con todos los usuarios que quieras. Hay un límite mensual de tráfico de 1 TB al mes, pero con 100 GB de espacio, salvo que hagas cosas extrañas es más que razonable, y en cualquier caso si te pasas de tráfico no deja de funcionar, simplemente te lo ponen a velocidad cochinera.
Vamos, que pese a que ya tengo mi flamante Nextcloud montado en local, no he podido resistirme a al menos probarlo. El alta es muy sencilla: escoges plan, pones la VISA, y en apenas unos minutos te crean tu instancia de Nextcloud, te asignan un dominio raruno tipo nx1234.your-next.cloud, y ya puedes entrar. Tienes por defecto un usuario administrador, y a partir de ahí creas todos los usuarios que creas, asignas cuotas y demás mandangas, igualito que si tuvieras tu propia instancia local. Por el momento todo funciona de lujo y las velocidades van bien. Hasta los clientes de Nextcloud permiten añadir la instancia adicional sin quitar la que ya tengas, por lo que ahora mismo tengo mi Nextcloud local y el de Hetzner.
¿Qué hacer a partir de ahora? Pues tengo el corazón partío, porque estoy muy orgulloso de mi Nextcloud local, pero tengo que reconocer que si llego a encontrar este hosting antes de montarlo, muy probablemente no me hubiera puesto a ello. Por poner ventajas e inconvenientes:
Nextcloud local
Hetzner
Ventajas
Más control sobre todo Mejor privacidad Gratis total
Mayor redundancia de datos en caso de desastre Todo nos lo gestionan unos señores de Alemania muy serios
Inconvenientes
Peor seguridad en tu casa que en un datacenter «pofesional» Más dedicación: dominios, desvío de puertos…
Cuesta dinero Los datos están en manos de un tercero Te fías de que los señores de Alemania sean serios
En fin, de momento voy a mantener los dos, y en un mes o dos decido a ver qué hago. En cualquier caso, para el que esté en una situación de querer (o tener que) irse de Dropbox y busca algo parecido a un precio razonable, la verdad es que lo que ofrece Hetzner es una opción muy interesante.
Llevo bastantes años usando Dropbox, y francamente estoy contento: a base de múltiples triquiñuelas tenía un espacio considerable, la web es amigable y usable, y las herramientas son más que correctas. Hasta había cliente para Linux, que no es algo habitual. Pero hace unas semanas los señores de Dropbox hicieron un cambio en las condiciones que, aunque aparentemente es pequeño, nos fastidia la vida a muchos: a partir de ahora, sólo se podrá vincular un máximo de tres dispositivos. Eso parece suficiente y razonable, pero luego empiezas a contar y no salen los números: móvil, más ordenador de casa, más ordenador del trabajo… ya sale justo. Como tengas más de un ordenador en casa, un portátil o una tablet, ya no llega. Además es un cambio sutil, porque como Dropbox no desconecta nada «a las bravas», ni te enteras. Yo me he dado cuenta cuando he formateado el móvil de fábrica porque se me arrastraba un poco, y al ir a instalar Dropbox me ha dicho que tururú, que tengo que desvincular unos cuantos dispositivos primero o nanay de la China.
¿Qué hacer ahora? Bueno, la solución obvia (y hacia donde barre la compañía) es contratar un plan de pago. Que la verdad no es descabellado, y en el pasado me había tentado: 9 euritos al mes, y tienes nada menos que 1 TB. Es un precio razonable, lo que pasa es que no necesito tanto espacio (ahora mismo vivo muy bien con mis 20 y pico GB) y, lo peor, en casa somos varios que usamos Dropbox. Como no hay ningún plan familiar, eso quiere decir 9 eur/mes para cada uno, lo cual lo hace ya inasumible. Así las cosas, y antes de pasar por caja, me vino a la cabeza montarme el tinglado por mi cuenta, y de eso va esta entrada.
La primera opción que me sonaba de un «Dropbox libre que me pueda instalar en mi casa» era Owncloud. Ahora bien, resulta que en Owncloud hubo hace unos años un «cisma» similar al de LibreOffice/OpenOffice, por lo que ahora mismo tenemos Owncloud… y Nextcloud. Aunque la cosa es como un culebrón venezolano, y a día de hoy sigo sin tener claro cuál «tiene razón», resumiendo mucho el tema parece que la cosa fue así:
Nextcloud lo montaron los desarrolladores originales de Owncloud, que se largaron casi en masa, por tanto sería el más fiel al espíritu original, y los que controlan más el cotarro. Claro que según a quién le preguntes te dirán que sí, que fueron los originales pero se acabaron largando a otros sitios también.
Parece ser que el código de Nextcloud tiene más vidilla que el de Owncloud. Que luego los de Owncloud dicen que es que ellos acumulan más cambios en menos commits, y que realmente avanzan igual. A saber.
Nextcloud me parece un poco más libre y menos «turbio» que Owncloud. En este último veo como mucha tendencia a pedirte la VISA: la app de Android es de pago, hay características que sólo están disponibles en la versión de pago… En cambio en Nextcloud es todo libre y completo de principio a fin, y si quieres pagas el soporte. Me parece mucho más limpio y claro.
El logo de Nextcloud me gusta más, y la web me parece más clara e inteligible. No es un argumentazo, pero todo suma 🙂
Vamos, que me he decidido por Nextcloud, que me parece el «LibreOffice» de este caso. Pero vamos, que tampoco hay una gran diferencia entre los dos, por lo que el proceso para ponerse Owncloud me da a mí que sería prácticamente el mismo.
Una vez decidido qué vamos a instalar, hay que hacer la lista de la compra: necesitamos Nextcloud, una base de datos para que Nextcloud guarde sus cosillas, un servidor web (Nextcloud está hecho en PHP, supongo que nada es perfecto 🙂 )… Podría instalarlo todo a pelo, o tirar de contenedores Docker, y tenerlo todo en dos patadas. Un día de estos escribiré una entrada de cómo Docker es lo mejor que se ha inventado desde el pan de molde, pero de momento basta saber que permite tener montado en un plis plas un tinglado con varias aplicaciones interenchufadas entre ellas, con apenas cuatro líneas de texto y de una manera similar a las máquinas virtuales, pero sin serlo y por tanto gastando muchos menos recursos. Yo lo he montado usando docker-compose, que permite configurar los contenedores que necesitemos y sus dependencias usando un ficherito de texto, y la cosa es tan sencilla como esto:
El fichero prácticamente se explica sólo, pero básicamente defino dos contenedores:
Una base de datos MySQL, configurando la contraseña de administrador
El Nextcloud en sí, añadiendo variables para decirle que use el MySQL anterior, cómo conectarse a él, y un par de cosillas más
NEXTCLOUD_DATA_DIR: Dónde van a estar los datos de Nextcloud (los ficheros, vamos), en este caso /usr/local/data. Pero ojo, porque esta es una ruta interna del contenedor, que en realidad será un «alias» a la ruta real, que he definido en volumes, y que será el directorio de mi servidor donde quiero que se guarden los datos
NEXTCLOUD_TRUSTED_DOMAINS: Aquí le digo desde qué direcciones admitiré conexiones. Por defecto la cosa es muy estricta, y por seguridad sólo se admiten conexiones desde la propia máquina. Con esto puedo añadir las IPs de las máquinas que accederán, un dominio si voy a dar acceso externo, o lo que sea
Y con esto ya basta con ejecutar docker-compose up, y veremos cómo los contenedores se descargan, construyen, configuran y arrancan. Una vez arrancado, podemos ir con el navegador a la URL de la máquina en la que se ejecute docker, al puerto 8080, y entraremos a la pantalla inicial de Nextcloud. Como ya le hemos indicado la mayoría de cosas que necesita (base de datos, dónde guardar los ficheros), sólo hará falta crearse un usuario, y ya estará listo para funcionar.
Con esto tan simple ya tenemos Nextcloud en marcha y funcionando, pero sólo desde nuestra red local. Como la gracia es poder acceder desde cualquier sitio, o desde el móvil, hay que abrir el tema al exterior. Aquí hay mil formas de hacerlo, lo que he hecho yo es algo muy típico:
Me compro un dominio nextcloud.midominio.com, que apunte a mi router (por ejemplo gestionándolo con FreeDNS).
Configuro en el router todas las conexiones HTTP (puerto 80) y HTTPS (puerto 443) hacia mi servidor.
En el servidor tengo un Apache, que hace que todas las conexiones que vengan desde nextcloud.midominio.com se redireccionen hacia el puerto 8080 del servidor (que es donde escucha Nextcloud)
Para conseguir esto, tengo el siguiente site de Apache:
<IfModule mod_ssl.c>
<VirtualHost *:443>
ServerName nextcloud.midominio.com
<IfModule mod_headers.c>
Header always set Strict-Transport-Security "max-age=15552000; includeSubDomains"
</IfModule>
ProxyPreserveHost on
ProxyPass / http://localhost:8080/
ProxyPassReverse / http://localhost:8080/
# Fix the HTTP Authorization header so the Android app can login (https://github.com/nextcloud/server/issues/8956)
RewriteEngine On
RewriteCond %{HTTP:Authorization} ^(.*)
RewriteRule .* - [e=HTTP_AUTHORIZATION:%1]
RewriteRule ^/\.well-known/carddav https://%{SERVER_NAME}/remote.php/dav/ [R=301,L]
RewriteRule ^/\.well-known/caldav https://%{SERVER_NAME}/remote.php/dav/ [R=301,L]
LogLevel info
ErrorLog ${APACHE_LOG_DIR}/error.log
CustomLog ${APACHE_LOG_DIR}/access.log combined
# Certificados de Let's Encrypt
Include /etc/letsencrypt/options-ssl-apache.conf
SSLCertificateFile /etc/letsencrypt/live/backup.midominio.com-0005/fullchain.pem
SSLCertificateKeyFile /etc/letsencrypt/live/backup.midominio.com-0005/privkey.pem
</VirtualHost>
</IfModule>
Es la configuración básica para hacer de proxy inverso con Apache, con algún añadido para arreglar cosillas de Nextcloud que he ido encontrando en foros (las Rewriterules o las cabeceras añadidas). También está el tema de los certificados para usar HTTPS, pero eso ya es otro tema que no viene al caso aquí (y del que por cierto hablé hace un tiempo).
Y con esto más o menos ya está. Queda pulir algunos detalles que tengo que resolver (por ejemplo hay aspectos de la configuración de Nextcloud que no se pueden parametrizar en el fichero de configuración de docker-compose y habrá que hacerlo de alguna manera), pero ya iré actualizando el post según los vaya resolviendo.
De momento la verdad es que la impresión es muy buena. Me esperaba algo bastante chusquero y pedestre (por eso de ser libre y tal) pero estoy gratamente sorprendido por lo bonito, suave y agradable que es todo. De hecho toda la interfaz y funcionamiento es muy, muy parecida a la de Dropbox, y funciona igual o mejor (por ejemplo la compartición de archivos por enlace es mucho más transparente, en Dropbox te obliga a tragarte un diálogo de confirmación). Las aplicaciones tanto de escritorio como de móvil también funcionan de lujo, y estoy francamente contento. Que es fácil que acabe volviendo a Dropbox cuando se bajen del burro y ofrezcan un plan familiar decente, o al menos más granular que el actual (300 GB por 3 eur/mes, por ejemplo, sería fabuloso). Pero la verdad es que Nextcloud me lo está poniendo complicado, porque es verdaderamente agradable de usar, y encima con Docker muy sencillo de gestionar.
Bueno, por fin le he podido dedicar un poco de tiempo y amor a mi humilde herramienta para buscar duplicados en imágenes JPEG, y la hemos metido de lleno en el s. XXI migrándola a Python 3. Ya que estaba, y como las dependencias con librerías para que funcionase se estaban volviendo un poco complicadas, la he empaquetado y la he subido a Pypi.
Eso sí, al ir a subirla he visto que el nombre de imgdupes ya estaba ocupado por otra utilidad. Estaba ya movilizando a mis abogados para desatar la ira divina sobre el pérfido usurpador, cuando he visto que, pese a que yo ideé el nombre primero (y a mis commits me remito), el imgdupes de Pypi es un proyecto más que interesante, muy activo y que tiene el nombre bien escogido. Por tanto, y confiando en que el karma universal valore mi magnanimidad en este vida o en la siguiente, he decidido cambiarle yo el nombre a lo mío, y así no nos peleamos. Vamos, que imgdupes ahora se llama jpegdupes, que además es más preciso porque, en realidad, el pobre imgdupes nunca había soportado nada que no fueran JPEGs.
Pues nada, que ahora instalar jpegdupes (anteriormente conocido como imgdupes) es más fácil que nunca. Basta ejecutar:
sudo pip install jpegdupes # O pip3 si aún tienen ud python2 por defecto
Y ya se instalarán automágicamente todas las dependencias necesarias. ¿Todas? No, me temo que sólo las intrínsecas de Python. Aún hay un pequeño reducto de dependencias de sistema que se resisten a desaparecer, y aún es necesario instalar un par de cositas con:
Pero vamos, que la cosa se simplifica bastante, se puede usar pip (que siempre es más facilongo que andar haciendo git clone de repositorios), y encima usamos Python 3, que ya tocaba. Ahora, aprovechando que ya usamos cosas modernas, estoy echando el ojo a migrar el código a la nueva sintaxis de async/await de Python 3.6, que me da a mí que puede acelerar bastante las cosas.
También disculpen las molestias los que estaban usando el imgdupes actual. La versión viejuna, para Python 2, sigue estando en el repositorio actual de Github (que se sigue llamando imgdupes, eso sí que era lío cambiarlo) como otra rama. Eso sí, salvo fallos garrafales facilongos de tocar, dudo mucho que vaya a actualizar más esa versión, a partir de ahora todo lo haré sobre la versión en Python 3.